Last updated 10 February 2024
In many OCR scenarios, we’re interested in extracting tabular data
from an image scan. Regular OCR often fails at this task, returning the
content of the table simply as lines with numbers instead of as
structured data. But the Google Document AI ecosystem has specialised
processors with powerful form parsing and table extraction capabilities,
most of which can be leveraged in R with daiR.
To extract table data from a PDF or an image, we use the core
functions dai_sync() and dai_async as we would
with text (see the vignette on basic use), except we
need to use a processor of type FORM_PARSER_PROCESSOR
instead of the default type OCR_PROCESSOR.1 We then use the
function get_tables() on the response object or JSON file,
in much the same way as we would with get_text().
Activating a form parser processor
The first step toward extracting tables is to activate a processor of
type FORM_PARSER_PROCESSOR. Depending on your use history,
you may or may not have such a processor available already. You can
check with the following code.
processors <- get_processors()
any(grep("FORM_PARSER", processors$type))If this yields TRUE, you have one or more form parser
processors already. Assuming you only have one2, you can store the id
in a variable like so:
formparser_id <- unique(processors$id[processors$type == "FORM_PARSER_PROCESSOR"])If the earlier command yielded FALSE, you don’t have a
form parser processor, and you must create one. This is very easy to do.
Just run the following command, adding a unique name for your
processor.
formparser_id <- create_processor("<unique_display_name>", type = "FORM_PARSER_PROCESSOR")If the processor name has been taken, you will get an error to this
effect. If so, just retry with another name. When successful,
create_processor() returns the id of the created processor,
and we can capture it in the variable formparser_id. Double
check that it worked by viewing its content:
formparser_idIf still in doubt, run get_processors() again and
eyeball the output. The new form parser model should be there.
Synchronous processing with form parsers
Now that you have the id of an active form parser processor stored in
the variable formparser_id, you are ready to process
documents with it.
Let us test it on a pdf from the so-called Truth Tobacco Industry Documents, which contains four tables like this:
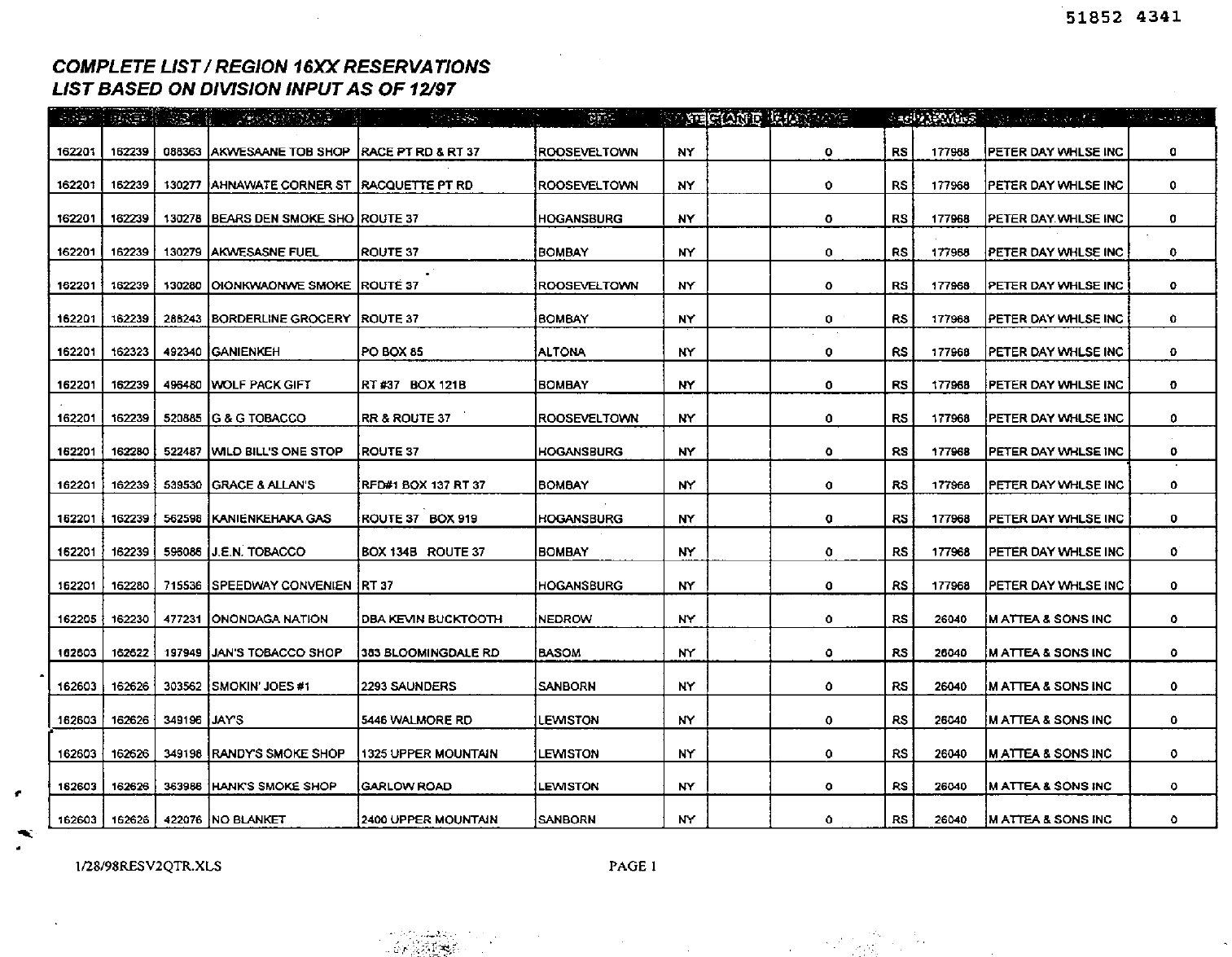
First we download it:
setwd(tempdir())
url <- "https://archive.org/download/tobacco_lpnn0000/lpnn0000.pdf"
download.file(url, "tobacco.pdf")All you now need to do is to run a regular dai_sync()
command, supplying the id of your form parser processor in the
proc_id parameter. Since it’s a four-page document, it may
take 20-30 seconds to process.
resp <- dai_sync("tobacco.pdf", proc_id = formparser_id)We can then pass the response object to get_tables(),
which will return a list with all the tables it found.
tables <- get_tables(resp)Running length(tables) suggests the list contains four
tables, which corresponds to the number of pages in the PDF. We can
inspect them individually like this:
View(tables[[1]])Or we can import them all into our global environment with
assign(), as follows:
Or we can save them all to .csv files like so:
for(i in seq_along(tables)) {
filename <- paste0("table", i, ".csv")
write.csv(tables[[i]], filename, row.names = FALSE)
}Either way, the result is pretty good. Here’s what the first table looks like in my RStudio before any cleaning:
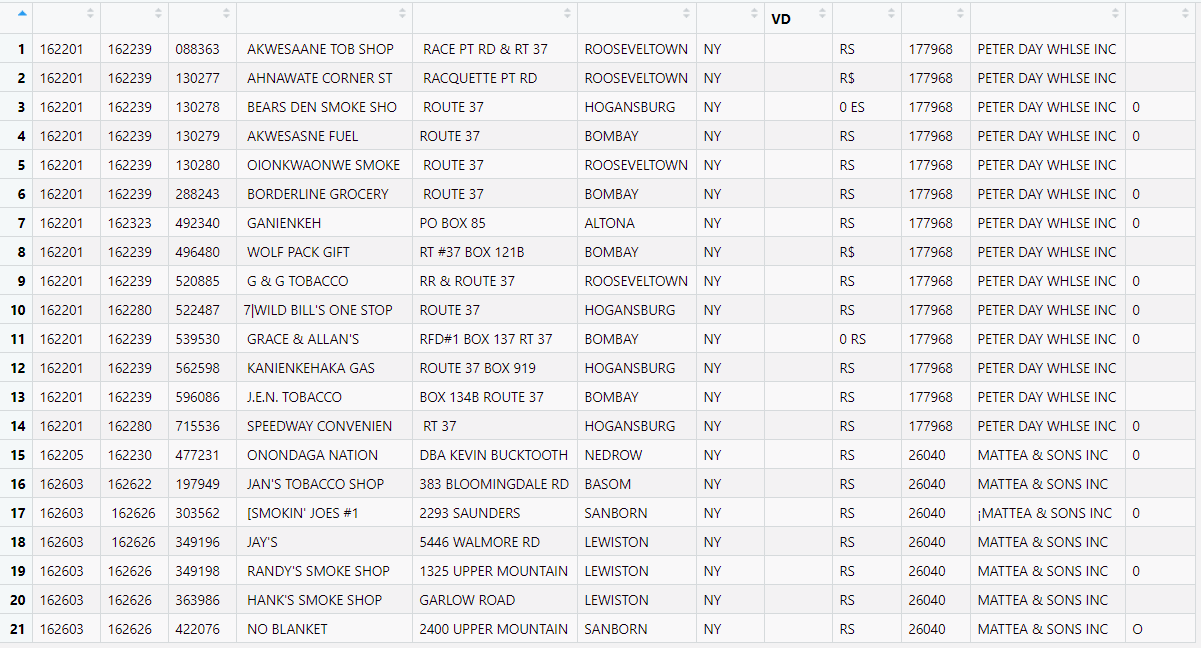
Asynchronous processing with form parsers
Asynchronous processing is very similar. First we upload the file to a storage bucket:
library(googleCloudStorageR)
gcs_upload("tobacco.pdf")Then we check that it arrived.
Then we pass the filename to dai_async, specifying that
we want the form parser processor to be applied. We also run
dai_notify() so we get a beep when the JSON file is ready
(it should take about 30 seconds).
resp <- dai_async("tobacco.pdf", proc_id = formparser_id)
dai_notify(resp)Then we download the JSON file. There probably aren’t many other JSON files containing the word “tobacco” in the bucket , so a quick Regex should find it.
contents <- gcs_list_objects()
our_json <- grep("tobacco.*json", contents$name, value = TRUE)
gcs_get_object(our_json, saveToDisk = "tobacco.json")Finally we supply the file to get_tables(), just making
sure to add type = "async".
tables <- get_tables("tobacco.json", type = "async")That’s all there is to it.
How good is it?
Most of the time you should get pretty good results. Don’t expect perfection, but do expect something that you can quickly clean up manually in Excel. However, the quality of the output varies, depending on a variety of factors, including
- the language (it works best on English)
- the complexity of the table (row and column spans are challenging)
- the amount of visual noise in the original document
- the resolution of the image passed to Document AI.
For optimal results, use a high-resolution scan, crop the image to remove everything except the table, and process asynchronously.
This way of getting tables was introduced in early 2024. Before then, the process involved calling another API endpoint (
v1beta2), which is whydaiRused to have a separate set of functions to deal with tables. On 31 January 2024, Google discontinued thev1beta2endpoint, making these functions obsolete. As a result,dai_sync_tab()anddai_async_tab()have been made defunct, whiletables_from_dai_response()andtables_from_dai_file()have been deprecated.↩︎If you have more than one form parser processor,
formparser_idwill contain more than one id. If so, either pick the first and best by runningformparser_id <- formparser_id[1]or choose a specific one manually and assign it to the variableformparser_id.↩︎